Taxonomy Building
Pascal Francq
April 23, 2012
To facilitate the access to documents in a large corpus, one approach consists in using a taxonomy, i.e. an organized concept hierarchy. The efficiency of the approach depends highly of the taxonomy used. If several general taxonomies exist, an adapted taxonomy provides a better search tools for a domain specific corpus. But building such a specific taxonomy can be resource-intensive if it is done entirely manually. Here I proposed a methodology to automatically build a first draft of a concept tree based on a corpus analysis.
Table of Contents
1 Introduction
A taxonomy is a hierarchy of classes, , organizing concepts used to categorize a set documents, . Each class is described with concepts (mostly a set of terms) which are more generic at the top of the taxonomy and more specific at the bottom of it. The hierarchy may be a tree (each class has only one parent), but it is not always the case. Finally, a taxonomy can build for general purposes, such as WordNet [1, 2], or adapted to a specific domain (for example to organize scientific papers in a given research field).
When humans build a taxonomy, they mostly following process:
- Analyze a document sample to identify an initial set of document topics.
- Represent each document topic by a set of concepts.
- Find relations between these concepts, in particular those who share parent-child relationships.
- Use the relations to distribute the concepts among a hierarchy of classes.
It is of course impossible to fully automatize this process since it needs a deep semantic analysis that cannot (actually) be done by software solutions. But it is possible to imagine some tools that provide some help for this process. In particular, the first two steps can be automatized. Moreover, it is possible to propose a concept tree based on a simple idea: if several topics share some concepts in their descriptions, the most they are dissimilar, the highest these concepts should be in the taxonomy.
2 The Methodology
To build a concept tree for a given corpus, the methodology proposed supposes two steps:
- Extract the main concepts from the corpus (or from sample of it).
- Identify the generality of each concept and infer parent-child relations.
The first step is based on a document clustering: the goal is to identify highly homogeneous topics (containing a “few” documents only). Once these topics computed, they are described thanks the centroid method which computes the average distribution of concepts in the documents of each topic. Moreover, it is also supposed that the most weighted concept of each topic description (for example the top ten most weighted) represent the main concepts of the whole corpus.
The second step needs to infer parent-child relations. Let us suppose that three clusters emerged from the previous step: described by (“os”, “unix” and “linux”), described by (“os” and “windows”) and described by (“os”, “unix” and “macos”). Intuitively, a thesaurus will have a top concept “os” with two child concepts “windows” and “unix”, this latest one having also two children “linux” and “macos”. To solve this problem, we use the Hierarchical Genetic Algorithms (HGA). There were developed to build a attribute tree where objects, described by attributes, are the leafy nodes. In our case, the objects are topics and the attributes are the concepts describing them. The “thesaurus algorithm” optimizes the average path length to reach a leaf node (a topic) of the tree (the thesaurus). The aim of this cost function is to balance the distribution of the concepts through the thesaurus in order to avoid big differences in the leaf node depths.
3 Experiments
Some experiments were done using the newsgroups corpus. This pre-categorized document corpus is supposed to provide an ideal clustering. Each topic is represented by the documents of a given category (one document can be assigned to multiples categories). For each topic, the description is computed with the centroid method and only the top ten weighted concepts are used.
Once the topic descriptions determined, the “thesaurus algorithm” is applied on them. Figure 1↓ shows the resulting tree. It seems a good base to build a real taxonomy (for example “god” and “christian” are considered as parent concepts for “christian religion” and “atheism”). But some words (such as “file”) are not very relevant for the hierarchy.
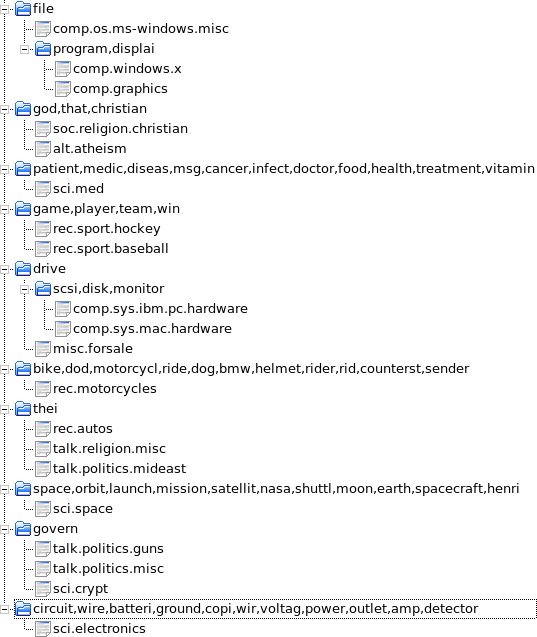
These experiments show two things: the “thesaurus algorithm” works, i.e. it builds a valuable concept tree, but the concepts selected to build it are not always relevant. This suggests that the selection of words used to build this thesaurus is a crucial issue in the methodology. The centroid method currently used is based on the the classical factors, but it is perhaps not the best approach to select the most interesting terms to build a thesaurus. Besides this problem, there are other opened questions. First, is the cost function actually used the best one to build a thesaurus? In fact, a completely different approach can be used to compute the cost function, such as optimizing the number of words used to build the hierarchy.
There are also questions that are specifically related to the HGA. For example, when a node must be chosen (in a given operator), the HGA manages them as an ordered list of their unique identifier. To ensure a greater diversity in the population (one of the main aspects of any genetic algorithm), the selection of the treatment order of the attributes should be randomized.
All these question should be investigated further in the future.
4 Implementation
Thee thesaurus algorithm is implemented in the thesaurus plug-in. In practice, it is a set of classes that inherit from the HGA adapted to build a hierarchy of document topics (the object) described by concept (the attributes).
References
[1] George A. Miller, Richard Beckwidth, Christiane Fellbaum, Derek Gross & Katherine J. Miller, “Introduction to WordNet: An On-line Lexical Database”, International Journal of Lexicography, 3(4), pp. 235—244, 1990.
[2] Christiane Fellbaum, “WordNet” in Theory and Applications of Ontology: Computer Applications, Roberto Poli, Michael Healy & Achilles Kameas (ed.), pp. 231—243, Springer, 2010.